ZStack Cloud Platform
Single Server Deployment with Full Features, Free for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

Through three major sections, tens of thousands of words, and more than 10 global representative customer ases
In the cloud platform ecosystem, APIs are the core link between product capabilities and developers. Accurate, complete, and up-to-date API documentation directly affects developers’ integration efficiency and user experience. However, as platform capabilities continue to evolve, the API surface keeps expanding and the pressure of documentation maintenance grows accordingly. Every API addition, change, or deprecation requires synchronized updates to the development guide, CLI reference, and API Explorer. As a large number of interfaces continue to change, how to keep documentation consistent with code, unify multiple publishing formats, and balance bilingual efficiency and quality has become the core challenge of API documentation engineering.
This article draws on the API documentation practices of ZStack ZCF (ZStack Cloud Foundation). It provides an in-depth introduction to the implementation of end-to-end API documentation automation from the perspectives of the multi-channel publishing architecture, the AI agent-based design approach, and the core challenges and solutions in engineering implementation.
ZStack Cloud Foundation (ZCF) is a private cloud solution that deeply integrates capabilities across multiple products. Through a unified portal, unified O&M, and unified computing resource management, it delivers a friendly and convenient full-stack management experience. ZCF exposes a rich set of RESTful APIs that span computing, operations, monitoring, alerting, and other domains.
Around the ZCF APIs, ZStack has built a multi-channel, multi-format documentation publishing system to meet user needs in different scenarios:
PDF manuals: For formal delivery scenarios, bilingual Chinese and English versions are provided. They cover request parameters, response fields, Curl samples, and SDK code samples for each API, making them suitable for offline consultation and project archiving.
HTML5 online documentation: For day-to-day development scenarios, developers can search and browse at any time in a browser to quickly locate the required API.
API Explorer: For interactive development scenarios, API Explorer is now live as an API reference section in the ZSite Documentation Center. It provides full-text search, categorized navigation, multilingual code samples, and version change markers (Added, Modified, Deleted), helping developers understand API evolution intuitively.
CLI reference manual: For O&M and automation scenarios, it provides the command-line invocation and parameter descriptions corresponding to each API.
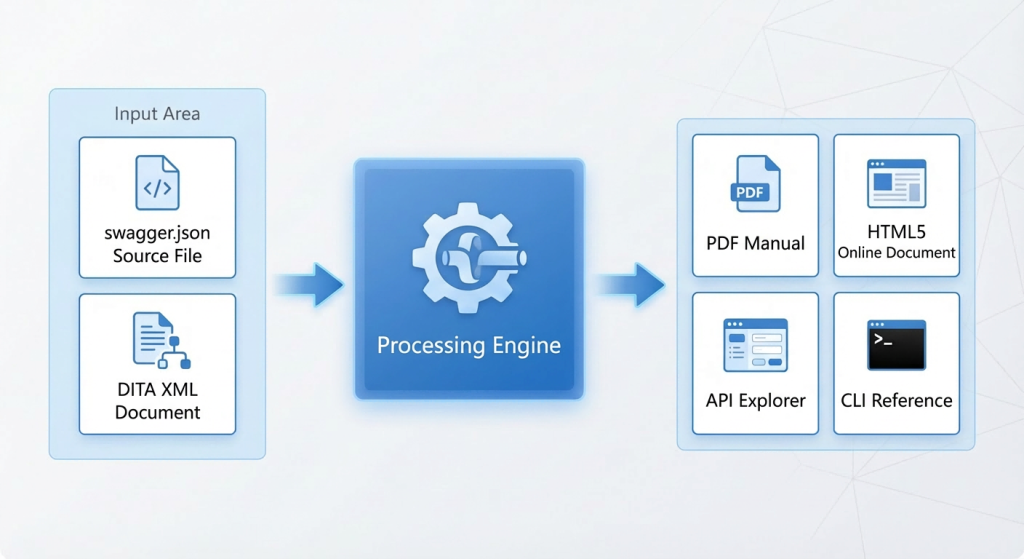
Figure 1. Multi-Channel Publishing Architecture of ZCF API Documentation
This publishing system is underpinned by two data sources. The first is the Swagger specification file (swagger.json), which the backend development team generates automatically along with the code. It is the single source of truth for API definitions and contains structured metadata such as the path, method, parameter structure, and response model of each API. The second is structured DITA documentation, which serves as the content foundation of the ZStack documentation system. It organizes textual content in XML and is compiled into PDF, HTML5, and other target formats through the DITA-OT toolchain.
Before automation was introduced, updates to ZStack API documentation relied heavily on manual work. This model had four prominent pain points:
Efficiency bottleneck: A single version iteration may involve changes to dozens of APIs. Writing and translating DITA alone usually takes one to two weeks or even longer, making it hard to keep up with a high-frequency release cadence.
Consistency risk: The documentation depends on Markdown references provided by the backend team. If they are inconsistent with the actual code, documentation errors can easily be introduced, leaving developers with conflicting information.
Quality fluctuation: Manual writing depends on individual experience. Documentation produced by different engineers varies significantly in structural conventions, terminology usage, and translation quality, and lacks a unified quality safeguard mechanism.
Lack of interactive usability was a previous gap: early workflows did not include API Explorer capabilities, so there was no unified online interactive experience; with the ZSite Documentation Center and API Explorer now live, this capability is available through the online documentation portal.
Given the continuous evolution of hundreds of APIs and the rigid requirement for synchronized multi-channel publishing, the traditional manual model is no longer sustainable. How to fundamentally connect the full documentation chain from Swagger to end users and make documentation update automatically whenever an API changes has become an urgent engineering challenge.
In response to these challenges, ZStack reexamined the API documentation production process from the perspective of AI agents: decomposing the manual operations of documentation engineers into orchestratable, verifiable, and reproducible automated stages, all scheduled and executed by AI agents. Unlike traditional CI/CD, AI agents possess semantic understanding. They can interpret Swagger and DITA specifications, decide whether to pass or block at quality gates, and provide natural-language feedback on the execution of each stage.
The overall architecture adopts a six-stage pipeline design, using Git changes to swagger.json in the backend code repository as the driving signal to complete the closed-loop automation process from diff detection to end-user delivery.
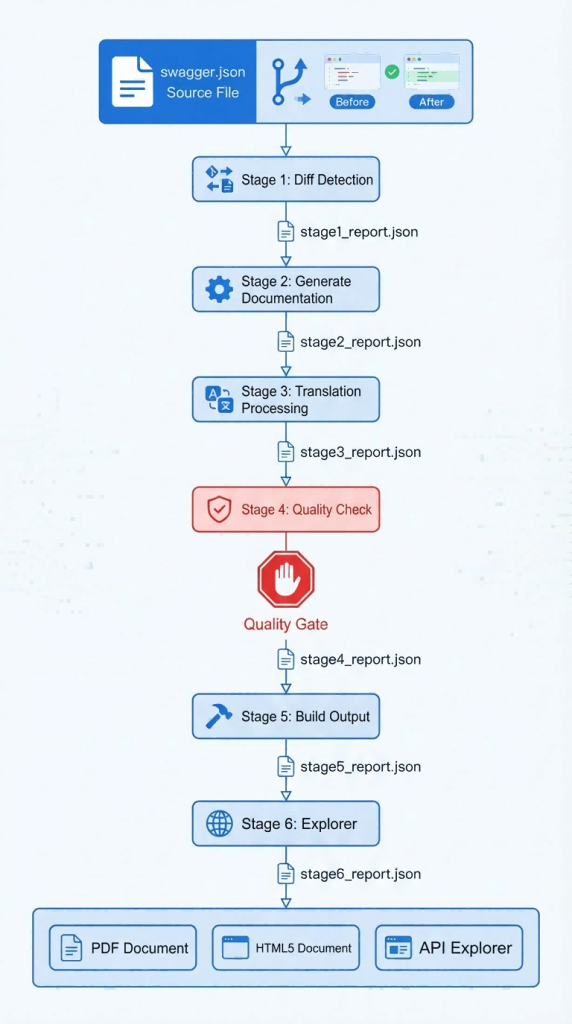
Figure 2. End-to-End Automation Pipeline Architecture
Stage 1: Diff Detection and Content Generation (Generate)
The pipeline starts with Swagger change detection. When a Git commit updates swagger.json in the backend code repository, the system automatically retrieves the versions before and after the change and performs a deep semantic comparison. By recursively resolving $ref references and allOf compositions, it accurately identifies whether each API operation is added, modified, or deleted and outputs a structured change list. It then applies different strategies to each change type: for added operations, it automatically generates complete DITA topics, including request parameter tables, response field tables, Curl samples, and SDK code samples, and inserts them into the Chinese and English Ditamap catalogs; for modified operations, it locates the existing files and regenerates the content in place; for deleted operations, it synchronously cleans up the files and catalog references.
Stage 2: Static Simulation Validation (Test)
At this stage, the generated DITA files undergo cross-validation between documentation and specification. The system parses API metadata from the DITA source files and compares it against the original definitions in the Swagger specification across seven dimensions: API name, request path, required parameters, request body fields, Curl sample, sample response, and SDK sample. This stage requires no backend services to be started. It is completed entirely through static analysis and can return validation results for each API within seconds.
Stage 3: Rule-Based Bilingual Translation (Translate)
At this stage, the validated Chinese DITA files are translated into English versions. Because machine-generated API documentation is highly structured and uses a closed vocabulary, the system adopts a purely rule-based deterministic translation strategy. It converts Chinese to English through a nine-step string replacement pipeline without calling any large language model. After translation, the system automatically scans the output files for untranslated Chinese characters as a safeguard audit for translation completeness.
Stage 4: Quality Gate (Review)
The quality gate is the core checkpoint of the entire pipeline and the only hard gate. Any review finding at the error level blocks the pipeline and prevents problematic content from entering subsequent compilation and publishing stages. The system applies 22 codified quality rules to both Chinese and English files, covering six categories of checks: document structure completeness (S), API content accuracy (A), title compliance (T), header consistency (H), inline tag correctness (L), and translation quality (Q). Each rule is implemented as a pure function that takes file content and a language identifier as input and outputs structured findings, ensuring that quality standards are traceable, reproducible, and independent of individual reviewers.
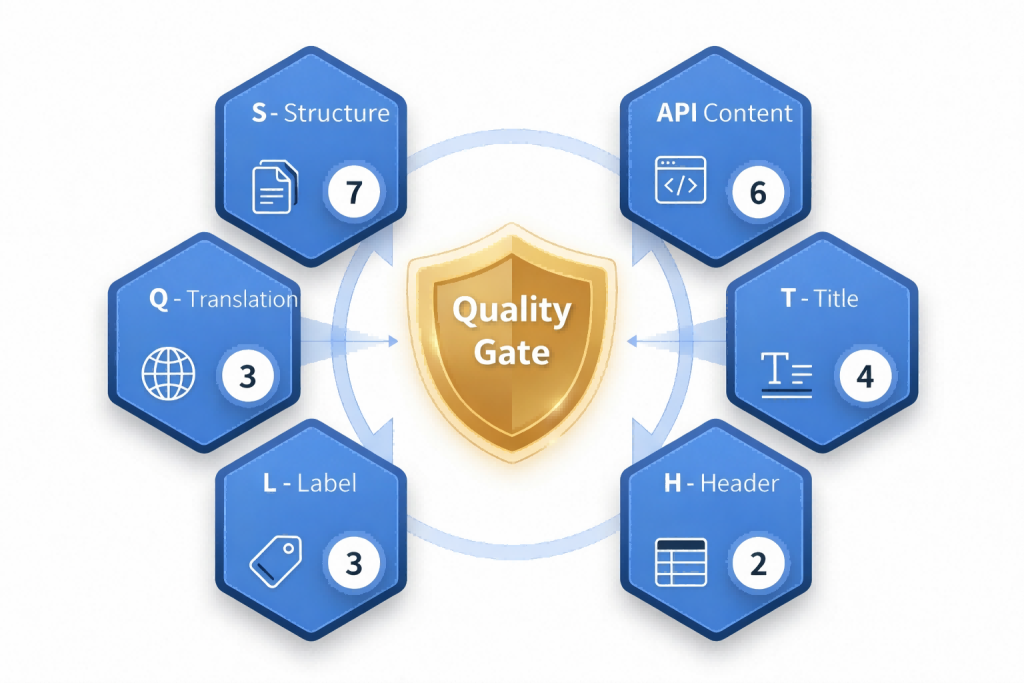
Figure 3. Six Quality Gate Check Categories
Stage 5: Bilingual Build and Publishing (Build)
After passing the quality gate, the system compiles the Chinese and English Ditamaps separately and uses the DITA-OT toolchain to generate PDF development guides. Build logs are streamed in real time during compilation, and structured results are extracted after completion, including success or failure, blocking errors, warning information, and artifact paths, for the agent to interpret and make decisions.
Stage 6: API Explorer Synchronization (Explorer)
In the final stage, changes are synchronized to the now-live API Explorer platform. API Explorer currently serves users as part of the ZSite Documentation Center. Entry: https://docs.zstack-cloud.com/docs/api-explorer/en. Based on Swagger diffs, the system generates a change manifest and then rebuilds the full set of data artifacts required by Explorer, including detail files for each API operation, multilingual code samples, categorized navigation trees, and full-text search indexes. Added and modified APIs are marked with change labels, while deleted APIs are retained under a “Recently Removed” category, ensuring that developers can perceive the complete evolution trail of the interfaces.
Across the entire pipeline, the following four design principles are applied throughout:
Incremental drive: Swagger diffs are used as the only trigger signal, and only API operations that have actually changed are processed, avoiding the resource waste and unnecessary file churn caused by full rebuilds.
Chained report passing: Each stage outputs a standardized JSON report. Downstream stages automatically extract input parameters from upstream reports, enabling loose coupling and independent debugging.
Determinism First: All six stages are built on deterministic Python logic to guarantee consistent outputs for the same inputs. AI participates only in orchestration and interpretation.
Single Source of Truth: swagger.json and DITA Ditamaps are used as the only sources of truth from which PDFs and API Explorer artifacts are derived uniformly, eliminating inconsistencies across channels.
1.Hybrid Intelligence: Strategic Division of Labor Between AI and Deterministic Rules
In API documentation automation, translation is a key capability throughout the entire chain, but the characteristics of different translation targets vary significantly. API names require strict consistency: the same operationId must map stably to the same Chinese title, otherwise developers become confused. API descriptions, by contrast, are natural language and place more emphasis on fluency and semantic accuracy. If both are handled uniformly by a large model, names tend to drift; if both rely entirely on rules, description quality is hard to guarantee.
For this reason, the system adopts a hybrid strategy of deterministic rules plus AI and precisely matches technical methods to the characteristics of each translation target. For API name translation, it uses a self-developed structured semantic parsing engine. It first maintains more than 570 exact override mappings to handle irregular naming. If no mapping is hit, it splits the operationId in PascalCase and performs verb recognition, By{Scope} pattern detection, and 4→3→2→1 level phrase matching in sequence to generate structured Chinese titles. The entire process is deterministic, ensuring consistent outputs for the same inputs. API description translation, meanwhile, is handled in batches by a large language model, with quality controlled through terminology constraints and a length limit of no more than 60 characters.
In addition, the principle of determinism first is also applied to the Chinese-to-English translation in Stage 3. Because the vocabulary set of machine-generated API documentation is closed, the system completes all translation through a nine-step string replacement pipeline and then audits any remaining Chinese characters by scanning Unicode ranges at the end. If the generator introduces new vocabulary in the future and the translation table is not updated accordingly, the audit mechanism raises an alert automatically instead of silently producing partially untranslated content.
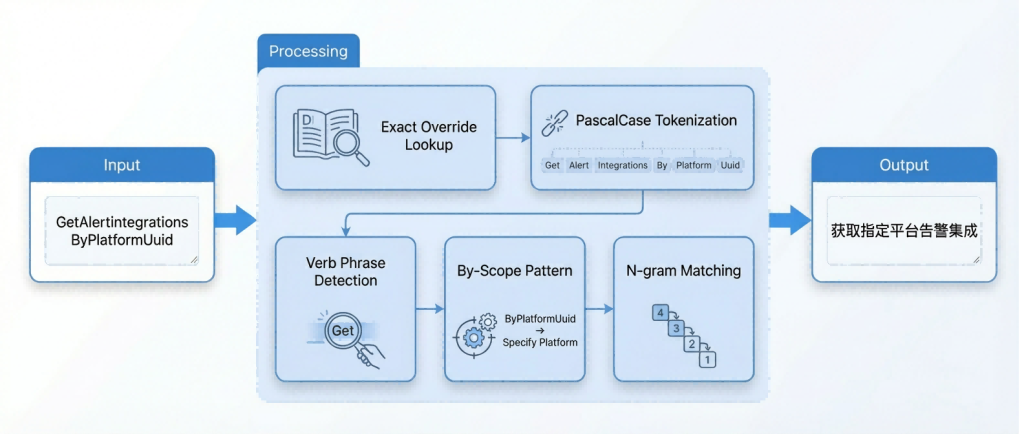
Figure 4. Structured Semantic Parsing Workflow for API Name Translation
2.Deep Semantic Parsing of Complex Swagger Specifications
In theory, the Swagger/OpenAPI specification is a clear standard for describing interfaces. In real engineering practice, however, swagger.json files automatically generated by backend frameworks often contain a large number of edge cases. Many ZCF APIs involve complex nested data models, and the system faces three typical challenges during parsing.
Circular references: Some data models form cyclic dependencies through $ref. The system introduces a visited reference set during recursive parsing and stops when a reference is encountered again, preventing infinite expansion.
allOf composition patterns: When multiple schemas inherit through allOf, naive merging loses constraints. The system performs a deep merge by taking the deduplicated union of required fields and recursively merging properties to ensure constraints are preserved completely.
Abnormal description text: Some descriptions are concatenated field names, such as alertintegrationplatformuuid. The system detects these cases with regular expressions and skips literal translation. It then splits the field according to camel-case rules and combines it with the terminology glossary to generate readable descriptions.
3.Codified Quality Gates and a Multi-Layer Validation Loop
In a fully automated pipeline, the most critical trust question is how to ensure that the quality of the generated documentation does not fall below the standard of manual writing. Traditional solutions rely on manual review, which is time-consuming and inconsistent from one reviewer to another. The system builds a three-layer progressive automated quality assurance system that turns quality standards from experience into code.
The first layer is the static simulation validation in Stage 2. It performs seven-dimensional cross-validation between Swagger and DITA, covering names, paths, parameters, request bodies, Curl samples, responses, and SDK samples, and can detect deviations without starting any services. The request body is validated with a dual-source strategy based on both parameter tables and Curl samples to cover different generation paths.
The second layer is the codified quality gate in Stage 4. The 22 rules cover structure, content, format, and translation quality and are implemented as pure functions. Chinese and English files are reviewed in the same round, and any error immediately blocks the pipeline, preventing problems from entering PDF builds.
The third layer is runtime documentation-interface consistency validation. After publication, the documentation is compared against the actual running API services across multiple quality dimensions, such as request parameters, response structures, and sample data, using runtime behavior as the final basis for validation. The three layers progress step by step: static comparison ensures that the documentation matches the specification, codified gates ensure that the documentation meets engineering standards, and runtime validation ensures that the documentation matches actual behavior. Together they form a closed quality loop from generation to publication.
In addition, for the small number of cases where the Swagger schema itself is defined incorrectly, for example when the response model structure does not match actual API behavior, the system provides precise schema override patches. These patches correct the issue during parsing, moving the fix for business-logic discrepancies forward to the data source layer instead of repeatedly patching the downstream generation stages.
1.End-to-End Automation with Significant Efficiency Gains
AI agent-based end-to-end automation compresses the API documentation update process from one-by-one comparison, manual writing, separate translation, and separate builds into a single workflow in which a backend Swagger change triggers automatic follow-up across the entire documentation chain. In the actual workflow, the system monitors changes to Swagger files through Git version control and automatically triggers all subsequent stages as soon as a change is detected, requiring no manual intervention throughout the process. At the same time, the incremental drive mechanism ensures that the system processes only changed API operations rather than rebuilding everything, further improving efficiency. Whether for routine minor iterations or large-scale API changes, multi-channel documentation publishing can be completed quickly and stably.
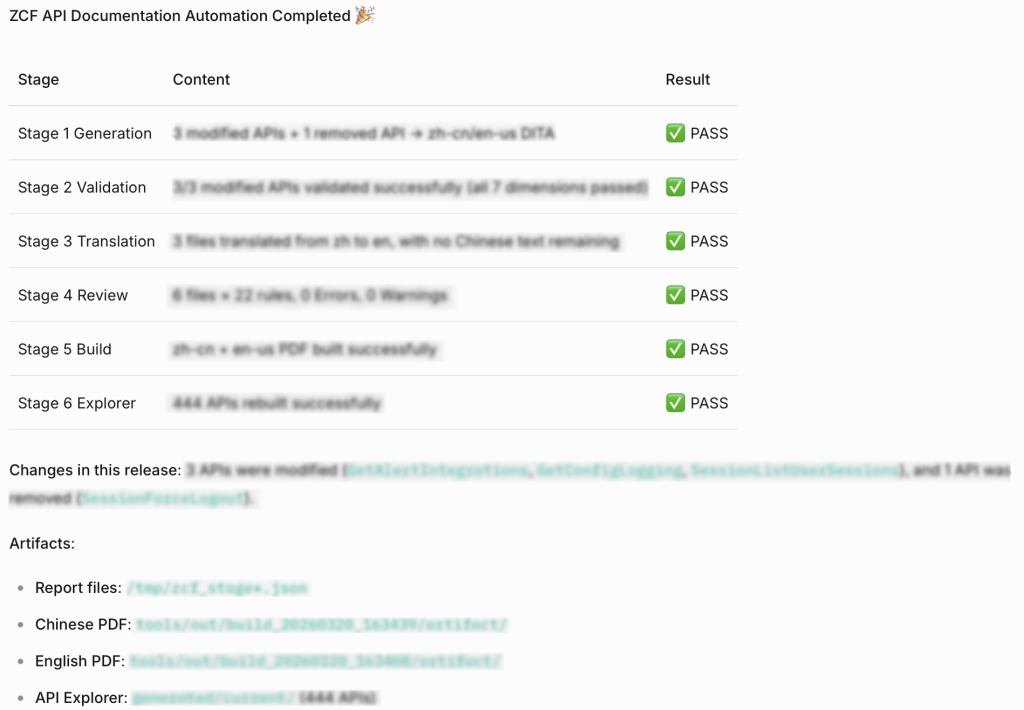
Figure 5. Pipeline Execution Process and Stage Reports
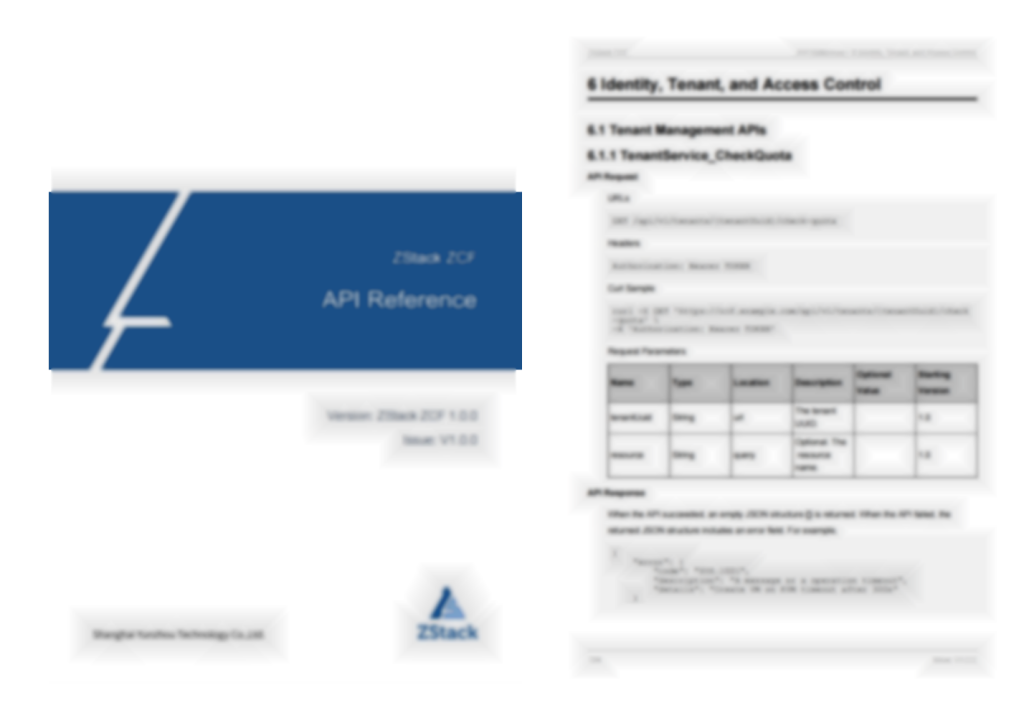
Figure 6. Automatically Generated PDF Development Guide Page
Figure 7. API Explorer (Now Live in the ZSite Documentation Center)
The ZSite Documentation Center is now live, and API Explorer is available as a core developer-facing section within it. From one documentation portal, users can search product documentation, browse API categories, find operations by keyword, view multilingual code samples, and track version changes, moving naturally from reading product documentation to exploring interfaces, checking examples, and understanding API evolution. To view ZStack API Explorer, visit https://docs.zstack-cloud.com/docs/api-explorer/en; for more product documentation, visit https://docs.zstack-cloud.com/en.
2.Controllable Quality and Unified Standards
The platform turns documentation quality standards from subjective judgments based on individual experience into the automatic execution of 22 codified rules, ensuring that every output document is reviewed with the same rigor. Chinese and English files are reviewed simultaneously in the same pass, and any error-level finding automatically blocks the pipeline, mechanically preventing noncompliant content from entering the publishing stage. At the same time, deterministic generation and translation logic guarantee reproducibility: with the same Swagger input, the system always produces exactly the same documentation content, regardless of when it runs or who triggers it, completely eliminating stylistic differences and quality fluctuation in multi-person collaboration.
The engineering evolution of API documentation is essentially a continuous pursuit of the quality triangle of accuracy, timeliness, and consistency. By introducing AI agents as the orchestration engine, the ZStack documentation team has connected the full chain from Swagger specification changes to multi-channel documentation publishing into an automated pipeline and found a sustainable balance between efficiency and quality. This practice validates a technical path in which AI and deterministic engineering complement each other: AI contributes semantic understanding and intelligent decision-making, while deterministic rules protect the bottom line of consistency and reproducibility.
In the future, we will continue to explore more possibilities for AI in documentation engineering and look forward to working with industry peers to advance this direction together.